
Problem
Media organisations sit on enormous video archives, decades of broadcasts, interviews and press conferences, but the metadata is shallow: headlines and dates, sometimes a transcript, rarely anything searchable by meaning. A journalist hunting "comments by central bankers about inflation expectations between 2022 and 2024" had nothing useful to query, so a valuable asset went unused and reporters lost hours.
Thomson Reuters wanted to change that for their teams: surface the right clips by intent, not keyword, fast enough to be part of the daily reporting workflow, with summaries that respected editorial tone.
Process
The decision that made the product usable was to fight the latency-cost-quality triangle rather than any one component. Embeddings across an entire archive are expensive, summarisation tokens add up, and journalists want sub-second search, so early on we set a latency budget and designed every choice against it, cutting anything that didn't earn its milliseconds. That constraint drove chunking strategy, model selection per stage, and a caching layer, rather than chasing the most capable model everywhere.
I joined as the AWS engineer leading technical delivery. The work split into three streams:
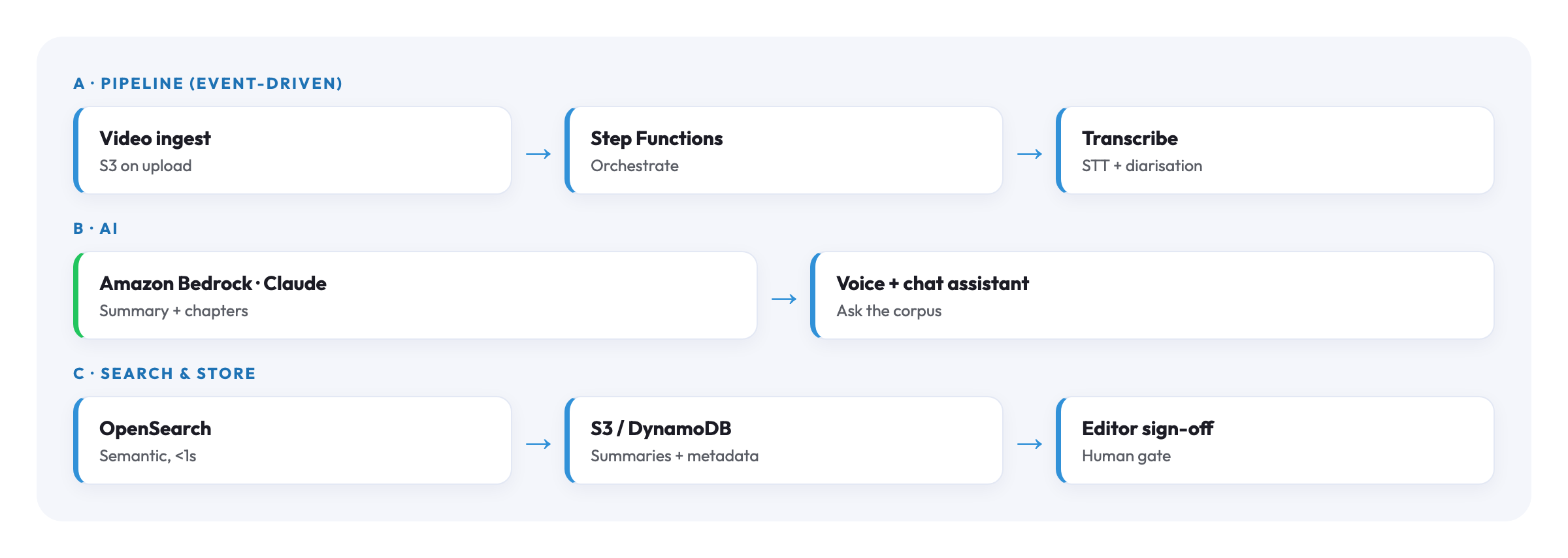
- Ingest pipeline. Take a video, extract audio, transcribe with timestamps, chunk by topical boundaries, embed each chunk for semantic search.
- Retrieval and summarisation. A query hits OpenSearch (vector + lexical); the top chunks plus context go to a Bedrock model, which produces a summary citing each clip with its in-video timecode.
- A reference UI. A React front-end demonstrating the search-and-summarise loop, built so customers could adopt it as an AWS solution and customise it.
I drove the architectural calls: semantic over fixed-size chunking, a smaller embedding model with a larger summarisation model, and the cache that made repeated queries cheap.
Outcome
Journalists could search decades of footage by meaning in under a second, turning an unused archive into a working reporting tool and saving the hours previously lost to manual hunting. The solution was published as an official AWS reference architecture and showcased at IBC 2024, the broadcast industry's flagship event in Amsterdam. Internal AWS teams have used it as the basis for further media-vertical work.
"It turned an archive we could barely search into something reporters actually reach for. That's real time back in the newsroom."
Editorial Technology Lead
Architecture
For engineersTechnical Deep DiveExpand
Pipeline architecture
Video uploaded → S3 │ ▼ EventBridge → Step Functions │ ├─ Extract audio (Lambda + ffmpeg layer) ├─ Amazon Transcribe (with speaker diarisation) ├─ Topical chunking (Bedrock: Claude small model) ├─ Embeddings per chunk (Bedrock: Titan / Cohere) └─ Index to OpenSearch (vector + keyword) Search query │ ▼ API Gateway → Lambda ├─ Hybrid search (kNN + BM25 in OpenSearch) ├─ Re-rank top-k by relevance score ├─ Fan-out context retrieval (timecodes ± window) └─ Bedrock summarisation (large model, RAG prompt)
Why semantic chunking
Fixed-size chunks (every 30s, every 1k tokens) create artificial boundaries: a speaker midway through a thought gets cut. Topical chunking, using a smaller model to find natural boundaries from the transcript, produced chunks that were each a self-contained idea. Empirically: ~25% lift in retrieval relevance over fixed-size at the same chunk count.
Hybrid search, not pure vector
Pure vector search misses exact-match queries. A journalist searching for a specific name wants lexical hits. We ran both vector kNN and BM25 against OpenSearch, then merged with a weighted reciprocal rank fusion score. The weight was tunable per customer.
Citation discipline
The summarisation prompt required the model to cite each claim with [clip_id:HH:MM:SS] markers, parsed back into clickable timecodes in the UI. We refused to render summary text without at least one citation per sentence, so anything ungrounded was filtered out. This kept the model honest.
Latency budget
| Stage | Budget | Achieved |
|---|---|---|
| OpenSearch query | 200ms | ~120ms |
| Re-rank + context | 100ms | ~80ms |
| Bedrock summarisation | 2s | 1.4–2.1s |
| Total p95 | ~2.5s | ~2.3s |
Search-only (no summary) was sub-second. The summary streamed into the UI as it generated, so perceived latency was ~600ms before the first token appeared.
Cost shape
Embedding cost scales with archive size (one-time per video) and is amortised. Summarisation cost scales with queries, the dominant ongoing line. We added a (query_hash, archive_version) cache so identical or near-identical queries within 24 hours returned from DynamoDB. Cache hit rate for the demo workload was ~30% within hours of a news event, higher when teams ran similar searches on the same topic.
Trade-offs
- No fine-tuning. RAG with strong citations gave better factual grounding and made the solution portable across customers without per-customer training.
- Vector store choice. OpenSearch ran inside the customer's own AWS account with their existing data-residency setup. Slower to optimise, but the right blast radius for this customer.